
Understanding "OpenSurfaces: A Richly Annotated Catalog of Surface Appearance" (ACM TOG - SIGGRAPH 2013 Conference Proceedings)
One of the greatest gifts that my advisor gave me when I was an undergraduate researcher was the habit of reading technical papers and publications on a weekly basis with the intent of discussing its contents. It’s helped me significantly in terms of picking up the core thesis of publications, news media, reports, and when jurying submissions for conferences, and is something that I’ve been started picking up again in recent months.
To be honest, writing these particular type of posts can take a lot of energy to just think and process the material in my own words. That being said, I feel it’s incredibly important for me to continue this habit as it is my responsibility to myself as someone with a research and practitioner background to continually engage with the tools, literature, and materials that are relevant to my field of work. In a nutshell, apologies for the long blog post - it’s part of the process of understanding the material (at least in my case), and I hope to get better at it over time.
“…In The Wild” Scene Understanding Papers
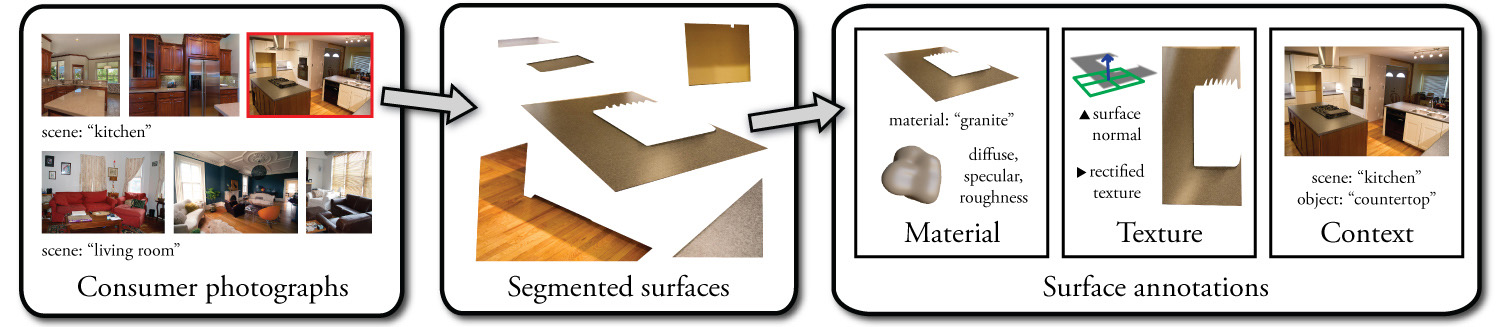 Yesterday I spent some time reading the “…in the Wild” series of publications by Sean Bell, Noah Snavely, Kavita Bala, et al., which are all grouped under the Cornell Graphics and Vision Group’s OpenSurfaces project. As stated on their website, OpenSurfaces is a large-scale data set of annotated surfaces created from real-world consumer photographs, presenting image/scene decomposition and understanding techniques to create said annotations for surface properties such as the material, texture, and contextual information. The approach taken with OpenSurfaces has since been extended in other papers, most recently in Shading Annotations in the Wild at the IEEE Conference on Computer Vision and Pattern Recognition 2017, which introduces a new public dataset for shading annotations for indoor scenes and using crowdsourced shading judgments and RGB-D imagery.
Yesterday I spent some time reading the “…in the Wild” series of publications by Sean Bell, Noah Snavely, Kavita Bala, et al., which are all grouped under the Cornell Graphics and Vision Group’s OpenSurfaces project. As stated on their website, OpenSurfaces is a large-scale data set of annotated surfaces created from real-world consumer photographs, presenting image/scene decomposition and understanding techniques to create said annotations for surface properties such as the material, texture, and contextual information. The approach taken with OpenSurfaces has since been extended in other papers, most recently in Shading Annotations in the Wild at the IEEE Conference on Computer Vision and Pattern Recognition 2017, which introduces a new public dataset for shading annotations for indoor scenes and using crowdsourced shading judgments and RGB-D imagery.
I’m hoping to go through each publication as I read them, with a collective thesis tying the varying papers together at some point down the line. As of now, those papers are as follows:
- S. Bell, P. Upchurch, N. Snavely, and K. Bala. OpenSurfaces: A richly annotated catalog of surface appearance. ACM Trans. on Graphics (SIGGRAPH), 32(4), 2013.
- S. Bell, K. Bala, and N. Snavely. Intrinsic images in the wild. ACM Trans. on Graphics (SIGGRAPH), 33(4), 2014.
- S. Bell, P. Upchurch, N. Snavely, and K. Bala. Material recognition in the wild with the materials in context database. Proc. Computer Vision and Pattern Recognition, 2015.
- B. Kovacs, S. Bell, N. Snavely, and K. Bala. Shading annotations in the wild. Proc. Computer Vision and Pattern Recognition, 2017.
With some optional reading (I might get to them):
- P. Krähenbühl and V. Koltun. Parameter learning and convergent inference for dense random fields. In ICML, pages 513–521, 2013.
- B.C. Russell, A. Torralba, K.P. Murphy, and W.T. Freeman. LabelMe: A database and web-based tool for image annotation. Int. J. of Computer Vision 77, 1-3, 2008.
My focus is on understanding the implementation, but if there’s time or find it necessary to discuss results in a blog post I’ll try or follow up with an update down the line.
OpenSurfaces: A Richly Annotated Catalog of Surface Appearance
OpenSurfaces, the first public data set in this series published by Sean Bell, Paul Upchurch, Noah Snavely, and Kavita Bala, was created with the intent of addressing the limitations of visualizing and modeling surface appearance in context and with rich detail derived from surface properties such as the material, texture, and associated shading effects. This is critical as creating high fidelity appearance of objects and surfaces in real-world scenes is determined by a wide range of surface properties.
There is a limited subset of tools that considers the broad range and ease of use for material and texture application which, at the base level, can be covered by manual annotation on forums such as Houzz’s. Doing so requires multiple iterations of participants having to tag elements and provide writeups on materials design and context details, with both processes requiring a method for standardization of association. Being able to parse materials and surface appearance efficiently would allow for a wide range of visualization applications, including more efficient search queries for materials respecting certain critera, automated recognition of materials in a scene, surface retexturing and editing using image segmentation techniques, and whether materials go pair with each other in application. With OpenSurfaces, Bell, Upchurch, Snavely, and Bala provide a rich, labeled open-sourced database for surface appearance properties for indoor scenes using an intelligent image-based scene understanding and a multi-stage annotation pipeline empowered by crowdsourcing (e.g. through Amazon’s Mechnical Turk, or AMT).
How the Data is Represented and Annotated
Annotating surface appearances requires understanding how real-world surfaces are characterized, which can be done in many ways. One can describe materials in terms of increasing order of complexity and/or specificity, material categories, image examplars (for structure analysis and transfer), and BRDFs models and measurements. When it comes to representing the data it was important to consider what type of representations were appropriate for certain applications. For example, a categorical database is more appropriate for material recognition tasks whereas an application that requires search queries may require more finely contextual feature descriptors. As such, the final OpenSurfaces surface representation includes:
- Material: A material name, and reflectance parameters including diffuse albedo, gloss contrast, and gloss roughness, represented with a a simple parametric BRDF model.
- Texture: A surface normal and rectified textures (derived from whether the surface region is planar).
- Context: The object name for the surface, and scene category for in which the surface occurs.
- Quality: Segmentation quality (how well was the object decomposed from the image scene), and a planarity score to determine whether the textures in the photo are significantly foreshortened by perspective.
The OpenSurfaces Annotation Pipeline
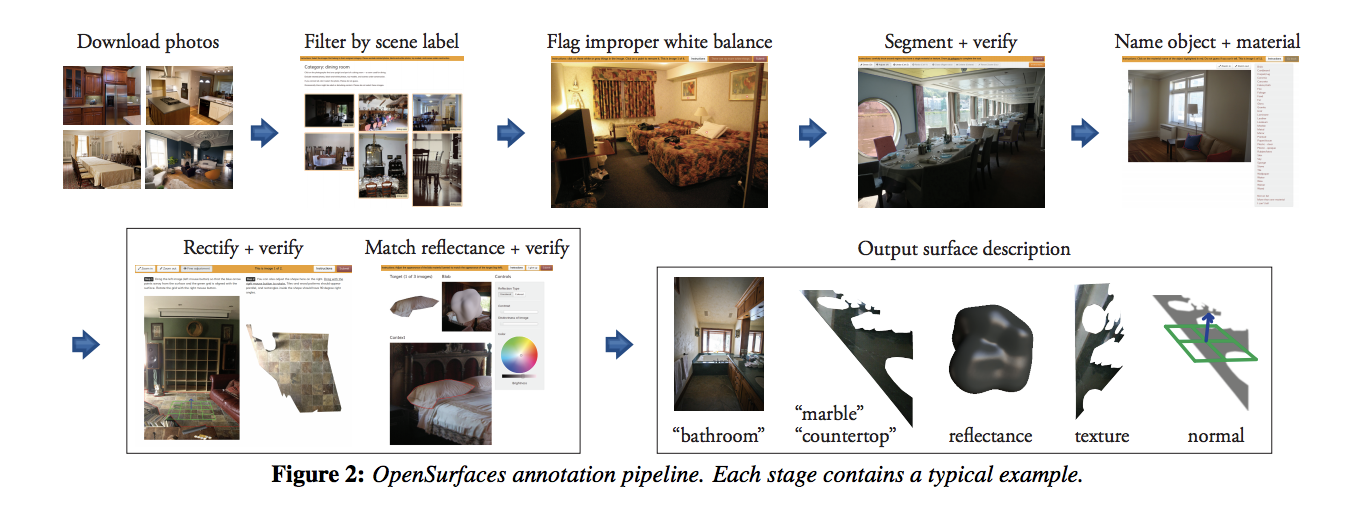 At a high level, OpenSurfaces’ annotation pipeline boils down to finding the right set of images with respect to certain criteria (scene category, color constancy), performing the material segmentation operations to decompose objects from the scene image, and doing the material recognition and appearance matching operations for annotation. Going one level down decomposes these steps into multiple stages that are required to get the correct from the scene images:
At a high level, OpenSurfaces’ annotation pipeline boils down to finding the right set of images with respect to certain criteria (scene category, color constancy), performing the material segmentation operations to decompose objects from the scene image, and doing the material recognition and appearance matching operations for annotation. Going one level down decomposes these steps into multiple stages that are required to get the correct from the scene images:
Image collection. The collection step is automated to search for high-quality images of indoor scenes (on Flickr, in this case) using a list of room types, with additional criterion that these images are not subject to stylization and can be used for open-source projects. These images are then grouped by scene type and further filtered out to keep color JPEG high-resolution images that have a reasonable disk footprint and have focal length information needed for texture rectification.
For the purposes of the this study, the OpenSurfaces team chose to focus on select scene categories, such as the kitchen, living room, bedroom, bathroom, hallway, and family room among others. These criteria allowed the sample size to be condensed from 1,099,277 down to 92K quality images.
Filtering images by scene category. Automated search query semantics for images can lead to noisy results - in the example the paper cited, searching for kitchen images using the query “kitchen” can lead to images of a bar/restaurant named “The Kitchen”. Just as in cited previous work, there is a need to manually curate images in order to find the relevant ones. For this study, the OpenSurfaces team asked workers via AMT to look at a grid of 50 images drawn from a given scene category, and select all the images that belong to that category. This further pruned the sample size down to 25K quality images.
Flagging images with improper white balance. In addition to noisy search query semantics, the lighting conditions in the search results can be highly variable from photo to photo. As such, the team designed an additional step where the labelers are asked to click on objects that they believe to be white, which in turn is used to reject images with improper white balance and are thus significiantly distorted in color space.
Each selected pixel is converted to color space, which is a mathematical model derived from color-opponent theory that maps all perceivable colors along dimensions for lightness () and the color differences along between the red-green () and blue-yellow () range. If the median value of , then the user’s submission counts as one vote towards the photo being white balanced. The Caltech UCSD Binary Annotational Model (CUBAM), which implements the approach described in The Multidimensional Wisdom of Crowds [Welinger et al., 2010], then processes the full set scores to determine whether a given image is white balanced.
Note that because material recognition is still possible in distorted color spaces [Sharan et al.], OpenSurfaces uses white balancing to filter inputs for appearance matching.
Material segmentation. The OpenSurfaces team created a new interface for material segmentation where a labeler was presented with an image and instructed to segment six regions based on material and texture as opposed to object segmentation, with several examples shown to provide standard understanding that an ideal segmentation contains a single material or texture and is tightly bound around the material region. Once the participant has segmented regions from the image, the team postprocessed the results to create a set of disjoint shapes in order to the address cases where a large region of a single material contains a smaller region of a second material (such as a door with a handle). In the event that these regions do not intersect, the smaller region is cut out leaving the larger region with a hole; otherwise, three regions are created to capture cases where there are intersections. The output is then stored as a triangulated 2D mesh.
Voting for material segmentation quality. In order to deal with variance in segmentation quality, an additional task was added where labelers would vote on the quality of each segmentation, which would then be aggregated to generate a quality metric for each segmented surface region. Because voting is subjective, the OpenSurfaces team only accepted shapes as high quality if there is consensus in scoring. The OpenSurfaces team used CUBAM to filter for noise.
Naming materials. Annotating material names is meant to indicate the properties that give the surface its appearance. In their interface, the OpenSurfaces team allowed labelers to select from a set of 34 possible material names, using a closed-world paradigm in order to discretize labeling.
Naming objects. Annotating object names is important because it determines what type of object is being analyzed and annotated, which helps drive better analytics of object-material association, search results, and categorical descriptions. Again, the OpenSurfaces team limited the labelers to discrete set of labels, as their interest is mostly in categories objects involved in material design, such as structural elements and worktops. To handle noise in labeling results, a semantic object label is kept only if 3 out of the 5 labelers agree to the label.
Planarity voting. Understanding the geometry of a surface region is an important part of the scene understanding process. The OpenSurfaces team was interested in identifying regions with simple, planar geometry, as planar regions are very common and account for a subset of objects that may be of interest when it comes to structure/material transfer between images. To do so, they added an additional task where workers would vote on whether a given segment lies on a single plane. Again, each segment is shown to five labelers, and the results were processed in CUBAM to filter for noise.
Rectified textures. In order to create rectified textures, labelers are given an interface where they are shown a photo with a planar region annotated in red, with a small grid and a surface normal inside the region. The labelers are then instructed to adjust the grid until the normal looks correct and the texture looks rectified. Again, five users vote on both the original and snapped normals, with “correct” adjustments determining the usage of the snapped normal.

Apperance matching. The last task is to find the reflectance parameters that match the appearance of each segmented surface. A synthetic object is rendered alongside the surface to be matched (with the photo as a backdrop). There were several considerations to consolidate with respect to their interface:
- The choice of a synthetic scene for appearance matching is necessary, and the OpenSurfaces team had to choose a shape, material, and lighting to be rendered with the current user-selected parameters to give effective visual feedback.
- The OpenSurfaces team utilized a blob shape for the synthetic object due to improved perception of material reflectances [Vangorp et al., 2007].
- The team use environment maps with natural lighting statistics to improve material perception, such as the hig-dynamic range environment map of the Ennis-Brown House [Debevec, 1998], with other techniques being taken into consideration for future work [Karsch et al. 2011].
- Although the choice of material representation was a tradeoff between accuracy and ease of labeling, it was found that there was no preference between the Ward-based and microfacet-based models. As such, the OpenSurfaces team utilized the perceptual Ward model with an optimization for the grazing angle. Color matching was considered the harder past of the task; to accommodate, the OpenSurfaces team simplified their model for selecting diffuse and specular color, initialized the diffuse using k-means clustering to analyze and find the mean initial color, and allowed users to click on pixels to select the color directly.
- In order to run the application for appearance matching, the OpenSurfaces team prefiltered environment maps to obtain a diffuse map and 16 gloss maps at different roughnesses as sampled from the perceptual Ward model. The HDR prefiltered maps are then packed into RGBE textures and encoded as PNG files which are then used for texture lookup of diffuse and gloss components at render time.
- Again, quality is voted on, with the results aggregated via CUBAM.
What are the Use Cases?
There are multiple applications for having a rich, labeled database that’s structured in the same vein as OpenSurfaces.
Textures. The OpenSurfaces paradigm for scene understanding allows for a larger set of rectified real-world textures that can be utilized for texture synthesis, which is an improvement over using unrectified textures that can lead to artifacts of foreshortening when synthesized. As such, OpenSurfaces elements can be utilized as surface retexturing and structure/appearance transfer from surface-to-surface.
Informed scene similarity. With a better semantic tagging and richer annotations, the OpenSurfaces database allows for deeper and detailed image and material search queries based on material properties, texture properties, and/or context data to resolve the limitations that were discussed above for prevous data sets.
Future applications. At the time of writing this initial paper, the OpenSurfaces team were interested in broadening the scope of annotations within the the database to account more granular texture and material search (search-by-material) - for example, searching for particular degree of shininess/roughness in a material or identifying the type of fabric or paint utilized based annotations. This is useful for users interested in material design. In addition, the larger database can be analyzed for common co-occurences or relationships between certain materials, as well as their geographic and temporal trends.
These results can also be applied towards editing operations, such as synthetic object insertion into photographs that could use the material annotations for accurate compositing. This application can be extended to do the same for lighting and shading, all of which could be coupled towards automated scene editing that utilizes co-occurent relationships, parameters, and semantics with respect to the affected materials and textures.
Finally, more work can be done on the database to enable automatic classification of materials and material properties.